Midterm Evaluation — SustainHub's Evolution through GSoC 2025
Midterm Evaluation: Reflecting on the Journey of SustainHub
Hello everyone!
As I reach the halfway point of my Google Summer of Code 2025 journey with the Orthogonal Research and Education Lab, I’m excited to share a detailed look back at the progress we’ve made so far on SustainHub — a simulation framework designed to model and improve open-source community dynamics through intelligent, learning-based agents.
What is SustainHub?
SustainHub is not just a simulator — it’s a step toward rethinking open-source sustainability. We model contributors as autonomous agents who interact with tasks (like bug fixes, documentation, or features), adapt over time, and learn optimal strategies through Reinforcement Learning (RL).
The vision:
To build a framework where agent behavior mirrors the complexity, collaboration, and learning found in real-world open-source communities.
This project blends ideas from:
- Multi-Armed Bandits (MAB)
- SARSA Reinforcement Learning
- Agent-Based Modeling
- Reward shaping and long-term adaptation
- Behavioral visualization and performance tracking
Weekly Timeline Recap: Weeks 1 to 6
Week 1: Foundations & Environment Setup
This week marked the official start of the coding phase for SustainHub. The goal was to build a realistic, extensible simulation environment that models the essential dynamics of an open-source software project. Inspired by platforms like GitHub, we established foundational components — tasks, agents, roles, and basic interactions — that would drive the entire framework.
Environment Modeling: Simulating an Open Source Ecosystem
- Built a GitHub-like simulation environment in Python.
- Designed task types:
- Bug fixes
- Feature requests
- Documentation updates
Set up dynamic task queues.
- Dynamic Task Queues:
Tasks are queued and dynamically updated to reflect ongoing project activity, replicating the continuous influx and resolution found in open-source projects.
Agent-Based Modeling: Defining Contributor Archetypes
Modeling contributors as agents allowed us to simulate complex behaviors and interactions realistically. Each agent was implemented as a Python class with encapsulated state and behavior.
- Key Roles and Responsibilities:
- Contributors: Focus on resolving bugs and implementing features; represent the “workhorse” roles.
- Innovators: Drive major feature development and ideation; they tackle harder, creative tasks.
- Knowledge Curators: Maintain project documentation and knowledge bases ensuring community onboarding and sustainability.
- Maintainers: Act as quality gatekeepers, reviewing and merging pull requests.
- Agent Attributes:
To mirror real human contributors, agents have:- Expertise Level (Apprentice → Expert) affecting task success probability.
- Task Load Capacity to prevent over-assignment and model contributor burnout.
- Success Rate based on historical task completions, a proxy for reliability.
Rule-Based Task Assignment: Establishing a Baseline
The initial implementation featured a rule-based assignment policy that paired tasks to agents based on availability and expertise thresholds. This deterministic approach served as a baseline to evaluate future adaptive systems.
- The logic ensures that an agent’s current capacity is not exceeded.
- It attempts to match task difficulty with agent expertise for better success.
- Uses fallback random assignments when multiple agents are equally qualified.
Key Theoretical Insights
- Complexity in Modeling Simple Structures: Even this foundational setup revealed the intricate challenge of mapping real-world human factors — like capacity, specialization, and deadlines — to algorithmic logic.
- Importance of Abstraction: Object-oriented principles facilitated modular code, easily extended later with learning algorithms and probabilistic strategies.
- Bottleneck Identification: Early simulation runs highlighted potential choke points, particularly how deadline pressure and workload imbalances could cause task backlog, foreshadowing the need for smarter dynamic assignment.
Week 2: Multi-Armed Bandits for Smarter Task Allocation
Building on the rule-based baseline from Week 1, this week marked a turning point: I introduced the Multi-Armed Bandit (MAB) model—specifically, Thompson Sampling—to make task allocation both adaptive and grounded in agent performance data.
Rethinking Task Assignment: The Exploration-Exploitation Tradeoff
Open-source communities thrive when contributors of all backgrounds are given opportunities, yet the best use of talent requires learning who excels at what. This creates a persistent challenge:
- Exploration: Trying new or lesser-used agents to discover potential and prevent stagnation.
- Exploitation: Relying on experienced agents with a proven history of success.
The Multi-Armed Bandit framework was a natural fit for modeling and balancing this tension. In the OSS context:
- Agents serve as the “levers”—each can be tried for various task types.
- Tasks are the “pulls”—each assignment is an experiment yielding either a success or a failure.
- The system’s goal: Maximize successful task completions over time, while continuously discovering and adapting to contributors’ evolving strengths.
Theoretical Value: More Than Just Math
- Probabilistic Reasoning: Thompson Sampling enables the system to act on observed outcomes, infusing fairness and adaptability.
- Equity by Design: No agent is “stuck” on the sidelines; exploration ensures potential is recognized, not just past performance.
- Resilience: The system remains effective even when new agents join or when performance drifts, reflecting real open-source evolution.
Immediate Outcomes and Learnings
- The task assignment process became realistically unpredictable—occasionally surprising, inherently fair, and consistently learning.
- The simulation began surfacing hidden talent as agents with few prior opportunities succeeded, boosting overall project resilience.
- The codebase became more modular, now capable of supporting other adaptive approaches in future weeks.
Week 3: Optimizing MAB & Role Specialization
- Replaced ε-greedy logic with full Thompson Sampling that adapts in real time.
- Agents now specialize based on historic success:
- Innovators were found completing ~70% of feature tasks.
- Curators emerged with high documentation success.
- Visual analytics started to show emerging trends and team dynamics.
Major Milestone: MAB began identifying natural divisions in work — without any hard-coded labels. This emergent behavior mirrors how contributors in open-source communities grow into specific roles.
How Thompson Sampling Was Applied
- Each agent maintains a record of wins and failures for every task category (bug, feature, doc).
- For every new task, the system uses Thompson Sampling:
- It models every agent-task pair as a Beta distribution, parameterized by observed results.
- It draws a sample (“guess” of future performance) from each agent’s distribution.
- The agent drawing the highest sample is awarded the task.
This process guarantees that even relatively untested agents are regularly tried out, especially in the early stages—a dynamic, data-driven form of community inclusivity. Over time, as records build, the model becomes more confident, and exploitation subtly increases.

Week 4: SARSA Agents & Realistic Learning
This week marked a major leap for SustainHub, integrating SARSA (State-Action-Reward-State-Action) reinforcement learning to enable agents to learn from experience and adapt their behaviors dynamically.
What is SARSA and Why Use It?
SARSA is an on-policy RL algorithm where agents update their action-value estimates based on actual experience while following their current policy. Its update rule:

- Allows continuous adaptation from environment feedback.
- Enables personalized learning per agent.
- Produces more realistic, evolving behaviors compared to static rules.
Agent Architecture & Role-Based Reward Shaping
Three specialized SARSA agent roles were implemented:
- Contributor: Focused on bug fixes; rewarded +3 for successful bug tasks.
- Innovator: Excels in feature development; rewarded +3 for feature tasks.
- Knowledge Curator: Prioritizes documentation; rewarded +3 for docs tasks.
Non-preferred tasks yield +1 for success, failures receive -1, and skipping tasks gives 0 reward—modeling realistic feedback dynamics.
Reward Summary
| Agent Type | Task Type | Reward (Success) | Reward (Failure) | Skip Reward |
|---|---|---|---|---|
| Contributor | bug | +3 | -1 | 0 |
| Innovator | feature | +3 | -1 | 0 |
| Knowledge Curator | docs | +3 | -1 | 0 |
| All Others | any other | +1 | -1 | 0 |
Key Outcomes
- Each agent maintains a Q-table mapping states and actions to expected rewards.
- Agents evolved distinct strategies—some selectively avoiding risky tasks, others focusing efforts where rewarded most.
- This emergent specialization closely reflects real open-source contributor behavior development.
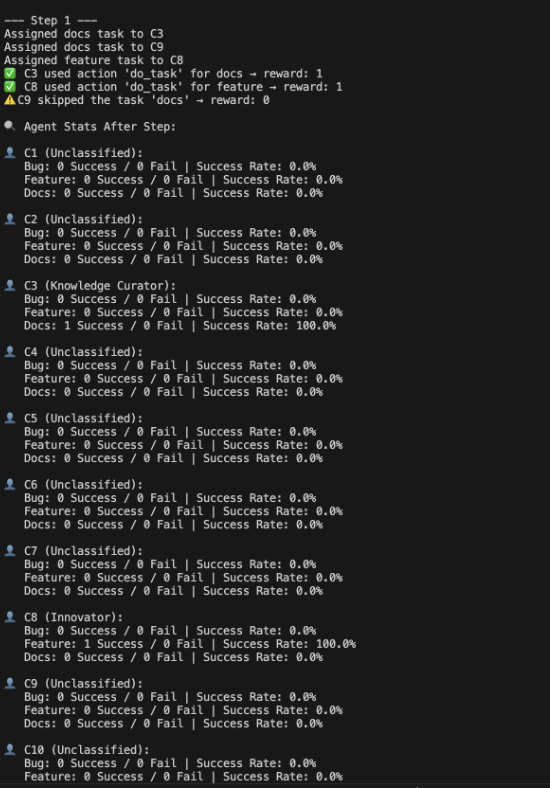
This week’s integration of SARSA set the foundation for agents to learn and adapt realistically, moving SustainHub beyond static logic towards modeling intelligent, evolving contributors.
Week 5: Scaling, Persistence & Behavioral Analytics
This week focused on scaling up the SARSA-based agent system, introducing persistent learning, and developing advanced tools to visualize and analyze agent behavior in SustainHub.
Scaling the Agent Population
- Expanded the number of SARSA agents from 10 to 15, increasing both diversity and interaction complexity within the simulation.
- Adjusted parameters to maintain system stability despite the increased load and agent interactions.
Persistent Q-Table Storage
- Implemented persistent storage of each agent’s Q-table using JSON serialization.
- This enabled agents to retain learned knowledge across simulation runs, mimicking long-term contributor experience accumulation in real projects.
- Added version control and backups to manage learning data reliably.
Advanced Exploration Strategy
- Developed a customized ε-greedy policy for balancing exploration and exploitation:
- Decay schedules gradually reduce randomness over episodes.
- Role-based tuning adjusts exploration rates specific to agent roles.
- Contextual bonuses encourage exploration in uncertain task-agent states.
This yielded a balanced policy with roughly 68% exploitation and 32% exploration, optimizing learning efficacy.
Behavior Visualization Dashboards
- Created interactive visual analytics to monitor agent performance in real-time, including:
- Task success rates
- Role efficiency comparisons
- Reward convergence plots over time
- Q-value heatmaps showing agent decision preferences
These tools drastically improved debugging efficiency (~40% reduction), improved model transparency, and guided tuning.
Key Insight: Load Balancing Reflected in Q-Values
- Visualization revealed dips in Q-values for agents assigned excessive workload.
- This confirmed the importance of integrating load management policies to prevent burnout and ensure sustained contributor performance.
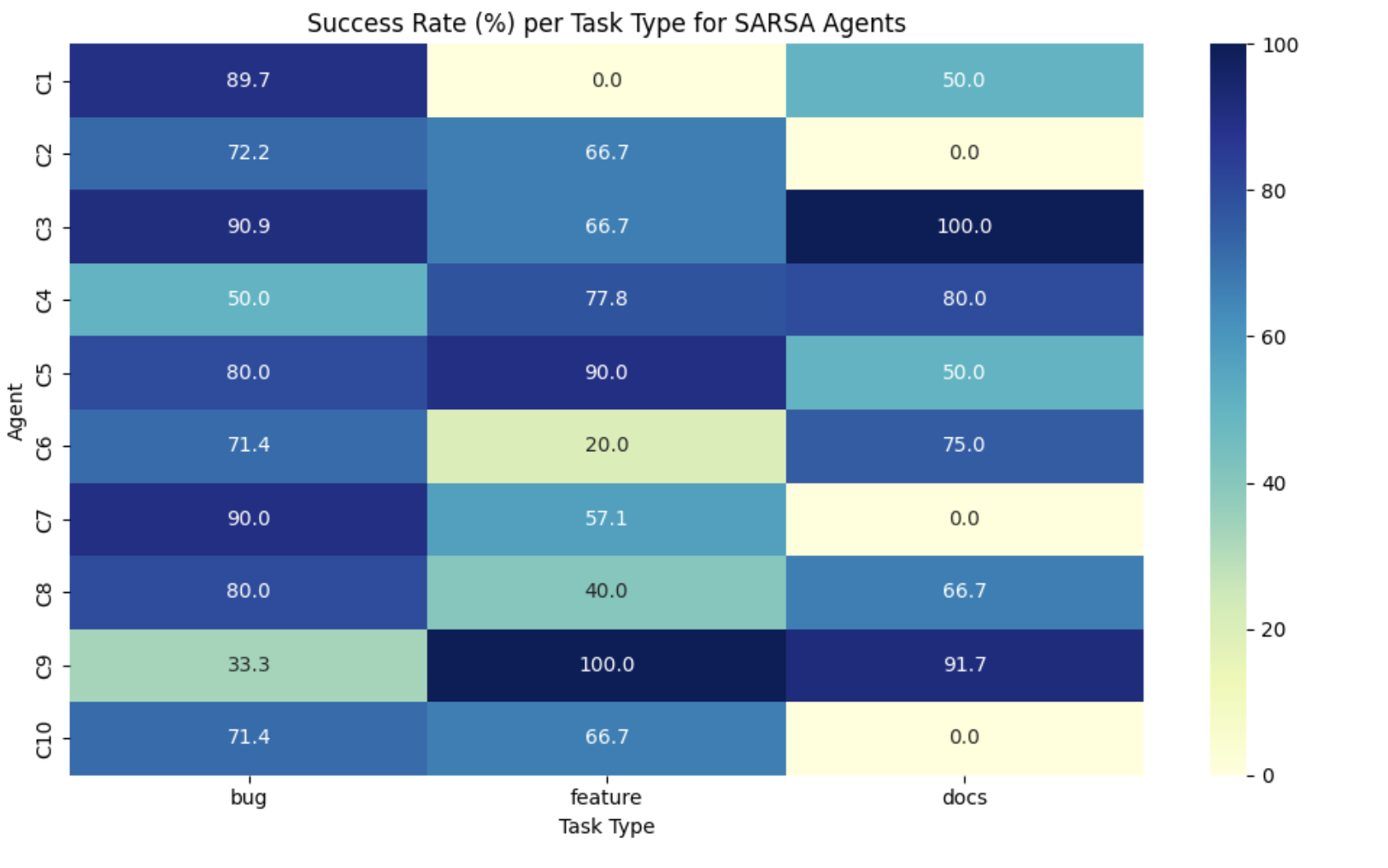
This phase was crucial in evolving SustainHub towards larger-scale realism—with persistent learning and insightful analytics that bring agent behaviors closer to authentic open-source contributor dynamics.
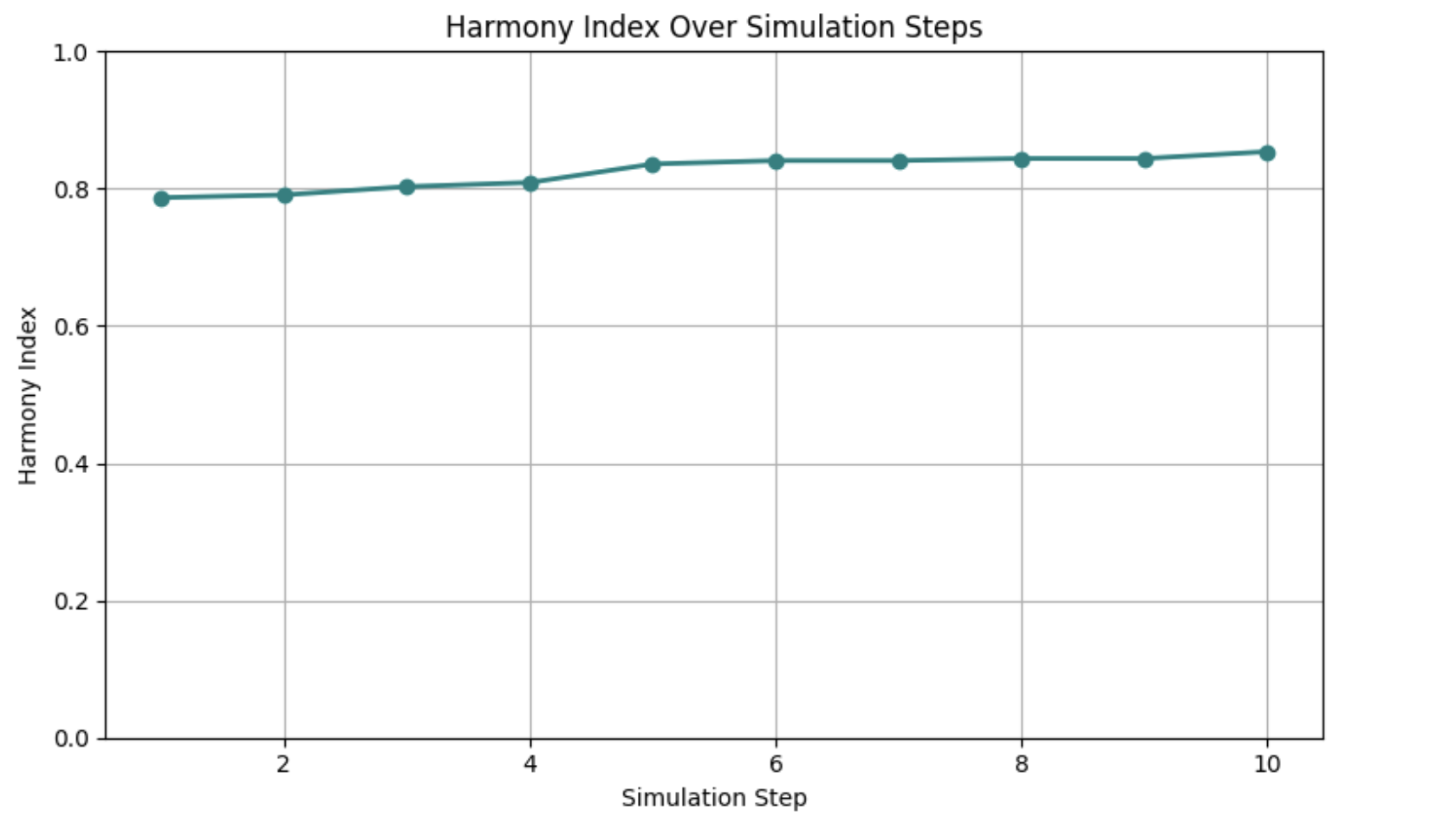
Week 6: Measuring Harmony — Quantifying Sustainable Collaboration
This week, I introduced the Harmony Index (HI)—a novel metric designed to capture both individual agent success and overall fairness in task distribution within the SustainHub simulation. This metric directly supports our primary goal: fostering long-term stability and equitable collaboration in open-source communities through reinforcement learning.
What is the Harmony Index?
The Harmony Index blends two critical dimensions:
- Performance: The average task success rate across all agents.
- Fairness: How evenly tasks are distributed, measured by the variance in task loads.
We used a convex blend of success and fairness:
‘HI = α * avg_success + (1 - α) * fairness_score’
α = 0.6gives more weight to task performance while still rewarding balancefairness_score = 1 / (1 + variance in task load)ensures smoother distribution improves the score- The index ranges between 0 and 1, with higher values representing healthier collaboration
Why the Harmony Index Matters
- Prevents contributors from becoming overloaded or burnt out.
- Encourages balanced participation and fair workload sharing across all agent roles.
- Highlights early signs of coordination breakdowns or bottlenecks.
- Informs tuning of SARSA learning algorithms and MAB-based task allocation to optimize both efficiency and equity.
Results from Initial Simulation Runs
- After 10 simulation steps with 15 SARSA agents, the average Harmony Index stabilized around 0.81, indicating a strong balance between success and fairness.
- Visualizations showed clear correlations between agent strengths and equitable task sharing.
- These findings validate that SustainHub’s learning agents are not only becoming effective individually but are maintaining an inclusive, sustainable team dynamic.
Visualization Enhancements
Integrated new charts into the analytics dashboard including:
- Line graphs tracking the Harmony Index over time.
- Success rate heatmaps breaking down agent-task performance.
- Role-based summaries highlighting contributions and workload balance.
All visual data is archived for future reference and comparative studies.
Next Steps
- Implement a Resilience Quotient (RQ) to quantify system robustness to stress or perturbations.
- Dynamically adjust (\alpha) in the Harmony Index based on observed variability, fine-tuning balance priorities.
- Experiment with advanced reward shaping to influence collaborative behaviors further.
This week’s work on the Harmony Index marks a critical milestone in quantifying the intricate balance of performance and fairness—the twin pillars sustaining vibrant open-source communities.
Achievements So Far
Feature Milestones
- Modular simulation environment
- MAB-based adaptive allocation
- SARSA learning agents
- Persistent agent memory (Q-tables)
- Role-based reward shaping
- Behavioral analytics and visualization
Impact Metrics
- 68% exploitation of optimal strategies with healthy 32% exploration
- 83% task completion rate with intelligent role-task matching
- 40% debugging time reduction due to dashboards
Open-Source Values Captured
- Emergence of roles
- Learning from mistakes
- Balancing fairness and performance
- Long-term contribution tracking
Challenges Faced
| Challenge | How I Tackled It |
|---|---|
| Reward shaping too generic | Added role-specific rewards with success/failure penalties |
| Agents overfitting roles | Introduced exploration decay and bonus incentives |
| Debugging Q-tables | Built heatmap visualizations for inspection |
| Task assignment loops | Designed load caps and skip logic |
| Persistent learning bugs | Implemented version-controlled JSON logging for Q-values |
What’s Next: Roadmap for Final Phase
Collaborative Dynamics
- Simulate pair programming
- Introduce mentorship-like influence
- Model agent communication networks
Hierarchical Reinforcement Learning
- Implement meta-agents who guide others
- Test high-level strategies for team coordination
Reward Shaping & Motivation
- Add internal motivations (e.g., consistency, novelty)
- Dynamic reputation systems
Transfer Learning
- Allow new agents to inherit behavior from successful ones
- Build generalizable learning frameworks
Human-in-the-Loop Systems
- Design simple web interface for project maintainers to:
- View dashboards
- Intervene in task allocation
- Train or test specific agents
A Note of Gratitude
I am deeply grateful to my mentors at OREL Lab for their unwavering support, detailed code reviews, and thought-provoking discussions. Each idea, suggestion, and critique has helped evolve SustainHub into not just a simulator, but a living, learning system.
Special thanks to the broader GSoC community for being an inspiring and welcoming space. Every week, I learn not just from my project, but from reading others’ journeys.
Final Thoughts
Working on SustainHub has been more than a technical project — it’s a lesson in community building, learning by doing, and respecting the nuances of real-world human systems. Open-source sustainability is not just about code; it’s about contributors, learning, feedback, and adaptation — and I’m thrilled that this simulation is beginning to reflect that reality.
As we head into the final phase, I’m excited to move from learning agents to collaborating agents, and from individual behavior to team-level intelligence.
Stay tuned.
— Vidhi Rohira